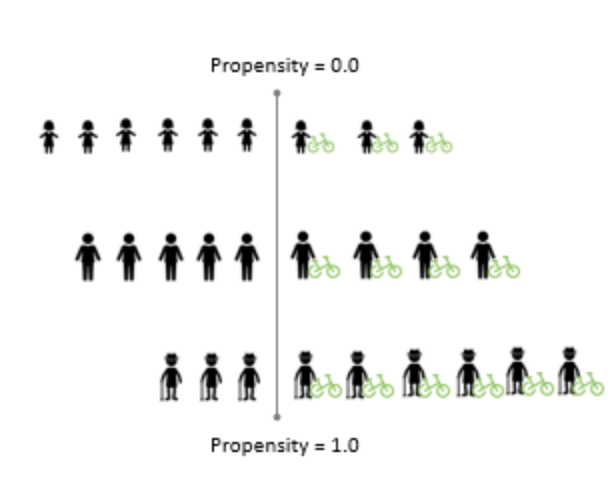
Propensity Score Weighting
Last updated
Last updated
# dowhy.causal_estimators.propensity_score_weighting_estimator _estimate_effect 함수 코드 일부
# ips_weight
self._data['ips_weight'] = (1/num_units) * (
self._data[self._treatment_name[0]] / self._data['ps'] +
(1 - self._data[self._treatment_name[0]]) / (1 - self._data['ps'])
)
self._data['tips_weight'] = (1/num_treatment_units) * (
self._data[self._treatment_name[0]] +
(1 - self._data[self._treatment_name[0]]) * self._data['ps']/ (1 - self._data['ps'])
)
self._data['cips_weight'] = (1/num_control_units) * (
self._data[self._treatment_name[0]] * (1 - self._data['ps'])/ self._data['ps'] +
(1 - self._data[self._treatment_name[0]])
)
# ips_normalized_weight
self._data['ips_normalized_weight'] = (
self._data[self._treatment_name[0]] / self._data['ps'] / ipst_sum +
(1 - self._data[self._treatment_name[0]]) / (1 - self._data['ps']) / ipsc_sum
)
ipst_for_att_sum = sum(self._data[self._treatment_name[0]])
ipsc_for_att_sum = sum((1-self._data[self._treatment_name[0]])/(1 - self._data['ps'])*self._data['ps'] )
self._data['tips_normalized_weight'] = (
self._data[self._treatment_name[0]]/ ipst_for_att_sum +
(1 - self._data[self._treatment_name[0]]) * self._data['ps'] / (1 - self._data['ps']) / ipsc_for_att_sum
)
ipst_for_atc_sum = sum(self._data[self._treatment_name[0]] / self._data['ps'] * (1-self._data['ps']))
ipsc_for_atc_sum = sum((1 - self._data[self._treatment_name[0]]))
self._data['cips_normalized_weight'] = (
self._data[self._treatment_name[0]] * (1 - self._data['ps']) / self._data['ps'] / ipst_for_atc_sum +
(1 - self._data[self._treatment_name[0]])/ipsc_for_atc_sum
)
# ips_stabilized_weight
p_treatment = sum(self._data[self._treatment_name[0]])/num_units
self._data['ips_stabilized_weight'] = (1/num_units) * (
self._data[self._treatment_name[0]] / self._data['ps'] * p_treatment +
(1 - self._data[self._treatment_name[0]]) / (1 - self._data['ps']) * (1- p_treatment)
)
self._data['tips_stabilized_weight'] = (1/num_treatment_units) * (
self._data[self._treatment_name[0]] * p_treatment +
(1 - self._data[self._treatment_name[0]]) * self._data['ps'] / (1 - self._data['ps']) * (1- p_treatment)
)
self._data['cips_stabilized_weight'] = (1/num_control_units) * (
self._data[self._treatment_name[0]] * (1 - self._data['ps']) / self._data['ps'] * p_treatment +
(1 - self._data[self._treatment_name[0]])* (1-p_treatment)
)
# ATE, ATT, ATC 에 따라 다른 가중치 부여 방법
if self._target_units == "ate":
weighting_scheme_name = self.weighting_scheme
elif self._target_units == "att":
weighting_scheme_name = "t" + self.weighting_scheme
elif self._target_units == "atc":
weighting_scheme_name = "c" + self.weighting_scheme
else:
raise ValueError("Target units string value not supported")
# 처치효과 계산
self._data['d_y'] = ( # 처치집단 가중치 * outcome
self._data[weighting_scheme_name] *
self._data[self._treatment_name[0]] *
self._data[self._outcome_name]
)
self._data['dbar_y'] = ( # 비교집단 가중치 * outcome
self._data[weighting_scheme_name] *
(1 - self._data[self._treatment_name[0]]) *
self._data[self._outcome_name]
)
est = self._data['d_y'].sum() - self._data['dbar_y'].sum()